
Have you been walking around the office, puzzled by all the chatter about ratty dish towels? Don’t worry; I’m here to clear things up! No, it’s not a new obsession with rags; people are fascinated by RAG, or Retrieval-Augmented Generation. So, what exactly is retrieval-augmented generation? Let’s dive in.
What is Retrieval-Augmented Generation (RAG)?
RAG is easy to understand if you unpack the terms in reverse. “Generation” refers to generative AI models, specifically large language models (LLMs) that generate text. “Retrieval-Augmented” means we retrieve information to enhance (or augment) the generation process.
Traditionally, when working with an LLM, you provide a prompt, and the model generates text based on its training data. However, if the required information isn’t part of the LLM’s training data, the output may be inaccurate or lack proper attribution, a problem sometimes referred to as “hallucinations.”

To address this, RAG involves retrieving relevant information based on the user’s prompt and combining it with the prompt to provide accurate answers and specific source attribution. In simple terms, we use the user’s prompt to search for relevant information and then have the LLM generate text based on both the prompt and the retrieved data.
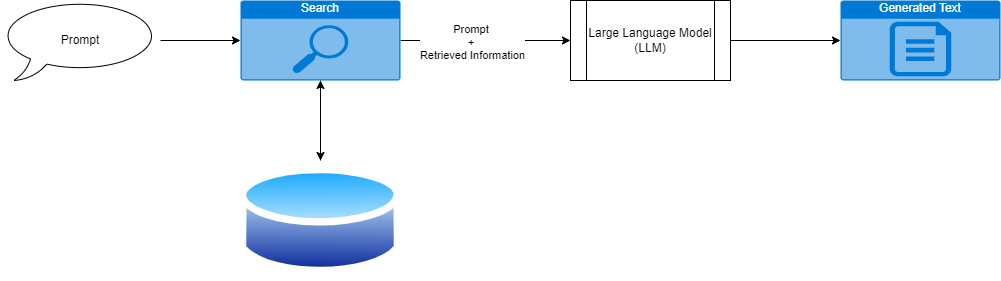
Implementing RAG
RAG isn’t as complicated as it sounds. It primarily involves adding an information retrieval capability to your system and making slight adjustments to how you prompt your LLM. Let’s break down these components.
Information Retrieval
In machine learning, vectors often represent numerical data used to train models. For instance, in speech processing, we use features like Mel Frequency Cepstral Coefficients (MFCCs). In natural language processing (NLP), vectors might numerically represent words. You might also encounter the term “embedding,” which refers to multi-dimensional data encoded in a vector. Embeddings capture richer information, like semantic relationships between words. Popular text embedding models include BERT and OpenAI embeddings.
For RAG, we want to find similarities beyond just individual words. We aim to match entire documents or large text segments. One popular model for this purpose is Sentence-BERT, which is easy to implement in Python:
from sentence_transformers import SentenceTransformer
embedding_fn = SentenceTransformer('paraphrase-MiniLM-L6-v2')
vectors = embedding_fn.encode(sentence_array)For a deeper dive into vectors and embeddings, you can read more here.
Querying for Similar Vectors
Once your data is converted to embeddings or vectors, finding similar ones is straightforward using similarity or distance metrics. One common metric is cosine similarity, which measures how similar two vectors are:
cosine similarity = (A · B) / (||A|| * ||B||)
cosine distance = 1 - cosine similarityThese metrics indicate the similarity or dissimilarity between two embeddings. More information can be found here.
Vector Databases
Now that we understand embeddings, let’s discuss where to store them. Popular vector databases include Pinecone and Milvus, but PostgreSQL with pgvector is also a viable option. For low-volume data, even a flat file can suffice. The main benefits of these solutions are performance and ease of use.
For this blog, I built a small RAG solution and found Milvus to be the easiest to set up. The Milvus Python libraries support Milvus Local, which creates a local database file, making prototyping straightforward:
from pymilvus import MilvusClient
client = MilvusClient(db_name)
client.create_collection(
collection_name=collection_name,
dimension=vector_dimension, # The vectors used in this demo have 768 dimensions
)Loading the Database
With our database set up, we can iterate over files, break them into sentences, generate embeddings, and load them into the database. Here’s a simple implementation:
data = []
id = 0
for file in os.listdir(data_path):
filename = os.fsdecode(file)
if filename.endswith(".txt"):
f = open(data_path + "/" + file, "r")
sent_array = re.split(r"[.!?](?!$)", f.read())
sent_array = [s.strip() for s in sent_array if s]
vectors = embedding_fn.encode(sent_array)
file_data = [
{"id": id, "vector": vectors[i], "text": sent_array[i], "filename": filename}
for i in range(len(vectors))
]
id += 1
data.extend(file_data)
client.insert(collection_name=collection_name, data=data)And that’s it! We’ve created our retrieval system with just a few lines of code.
Prompting and Searching
The final steps involve searching for relevant documents, extracting text, and sending it to the LLM along with a prompt.
Searching
Starting with a user prompt (e.g., “Tell me what this author thinks about RAG”), we generate a new sentence embedding and pass it to our database to find the most similar embeddings:
query_vectors = embedding_fn.encode(query_string)
res = client.search(
collection_name=collection_name,
data=query_vectors,
limit=1,
output_fields=["text", "filename"],
)This retrieves the text and associated filename for the sentence most similar to the user’s query. We can then open the file, extract the text, and send it to our LLM.
Prompting
With the source document and user query, we can generate an answer using any LLM. Here’s a sample prompt:
system_message = """You can answer questions based on a piece of source material. Given a question and text from an official source, answer the question using the source information in a clear, concise, and accurate way. Use paragraph form for your answer."""
user_prompt = f"question: {query}, source: {text}"Sending this to an LLM provider like Anthropic is straightforward:
import anthropic
message = client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=300,
temperature=0.3,
system=system_message,
messages=[
{
"role": "user",
"content": [{"type": "text", "text": user_prompt}],
}
]
)
response = message.content[0].text
Putting it Altogether
And there you have it. With less than 100 lines of code and a few off-the-shelf components, you can have a RAG system up and running. It may not be as simple as wiping down a countertop, but it’s pretty close. This technology forms the foundation of some of the biggest AI startups today, including Glean and Perplexity. So, don’t let RAG intimidate you—it’s easier than you think!
If you’d like to see my full implementation of RAG for WordPress blogs, you can find it here.