
If you’ve followed my previous posts, you might be under the impression that I’m against large language models (LLMs). However, in the words of my mother, “I’m just kvetching!” The truth is, I’ve been a devoted fan of LLMs for quite some time and have successfully integrated them into multiple customer-facing products. So, why the seemingly negative outlook?
The Challenges of LLMs
LLMs will undoubtedly accelerate your ability to deploy conversational AI and natural language based products and features. But as the old adage goes, “There is no such thing as a free lunch”.
No matter how passionate you are about LLMs, anyone who attempts to construct a production-grade product around them will inevitably learn that it comes at a cost.
Here are some challenges that come with LLMs:
- Nondeterministic behavior
- Lack of strong typing
- Struggles with abstract calculations
- Poor uptime
- Performance issues
- High cost
My aim here is to delve into each of these areas and offer some advice on how you can navigate around them.
Navigating LLM Pitfalls
Nondeterminism
Like it or not, commercially available LLMs all exhibit nondeterministic behavior, even with a temperature of zero. Why? There have been various theories, ranging from the temperature of zero not being a true zero, to floating point rounding errors that become magnified due to the autoregressive (i.e., recursive) nature of generative AI models. Regardless of the cause, it happens, and it’s something you’ll need to manage.
LLMs are increasingly taking the place of more traditional intent and entity systems like RASA or SPACY. These systems have historically relied on discriminative machine learning models (e.g., classification models) for intent and entity detection. In such a system, your intent classes and entity key/value pairs remain fixed, and the only errors you need to deal with are misclassifications.
However, the predictability of intent or entity classes, or even the associated values attributed to a particular entity, is not guaranteed when using an off-the-shelf LLM. For instance, even with specific prompts, we’ve noticed a variety of responses for intents like sharing a summary.
share_meeting_intents = {"share_summary", "share_meeting_summary"}The same variability applies to entities. Even more concerning, we’ve found that LLMs can’t guarantee consistency in entity values. Even if you instruct the LLM to return the associated input text exclusively, the model might attempt to produce more normalized data. For instance, a month like “June” could be converted to “6/1.”
To navigate these issues, treat your LLM solution like any other ML project and test it accordingly. This means having a substantial amount of ground truth data and comparing LLM responses to expected results. Because of the variability in responses, you’ll likely need to accommodate multiple valid alternatives for all of your expected classes. Post-normalization evaluation of entity values might be necessary to avoid grappling with every possible variation.
You might need to perform significant testing with generated test cases before launching to understand the range of potential responses for any given system. But even with thorough advanced testing, robust monitoring tools will likely be necessary to swiftly assess what’s happening in real-time with your customers. As you uncover failure cases, ensure that your code is structured in a way that allows you to quickly accommodate these new scenarios.
Tools like Label Studio can be helpful for building labeling solutions and labeling data. However, due to the high degree of variability, you might need to devise your own testing framework.
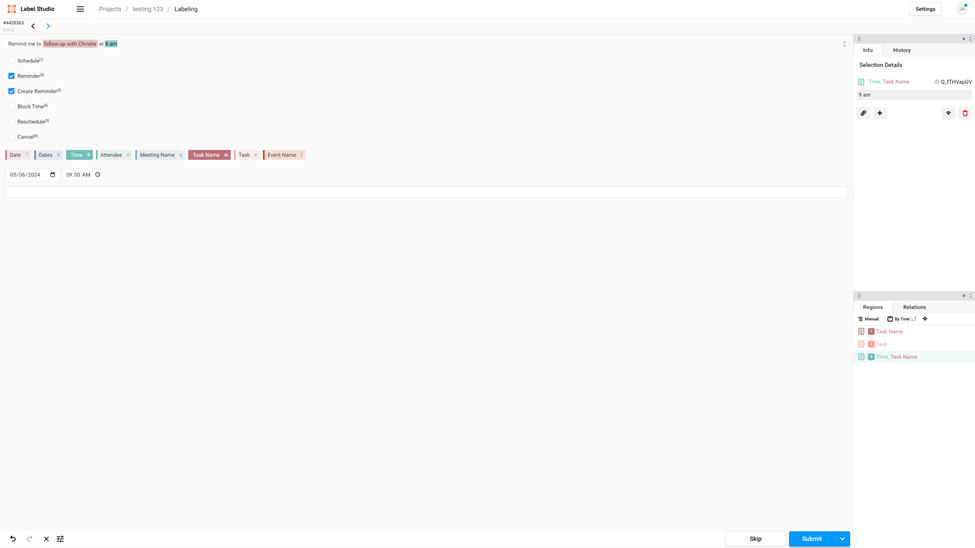
Lack of Strong Typing
LLMs output text, meaning none of the data can be considered strongly typed. For example, if a user says, “send an email to Jason”, we don’t definitively know who “Jason” is. Your system may be able to suggest possible “Jasons” for the user to confirm, but you’ll need to store and associate that strongly typed identifier (email address, ID, etc.) with the conversation.
There are several ways to address this problem. One approach is to pass back an ID to the LLM, ensuring it’s not regurgitated to the user. However, depending on how you’re using LLMs, this may not always be feasible. We also know that LLMs can hallucinate and there is always a chance that the ID you get back is not the one you started with.
An alternative is to maintain strongly typed context data associated with the conversation in a separate document store, like MONGO DB. This can help prevent repeated confirmation requests from the user.
Abstract Calculations
While recent models have shown improved functionality with tasks like math, LLMs still struggle with abstract calculations. It seems that the models are merely predicting next tokens without having learned to generalize any mathematical abilities.
For this reason, I suggest using LLMs to collect entity data but resort to a more reliable system for any abstract calculations. For instance, if you are doing any date / time calculations, it’s best not to rely on the LLM. Consider leveraging dedicated date / time NLP solutions like SUTime, Duckling, or build your own in Python.
Poor Uptime
Not to pick on OpenAI, but they have been known to have less than satisfactory uptime, which wouldn’t pass muster in most traditional SaaS businesses. OpenAI’s API currently reports two 9’s of uptime for the past 90 days.
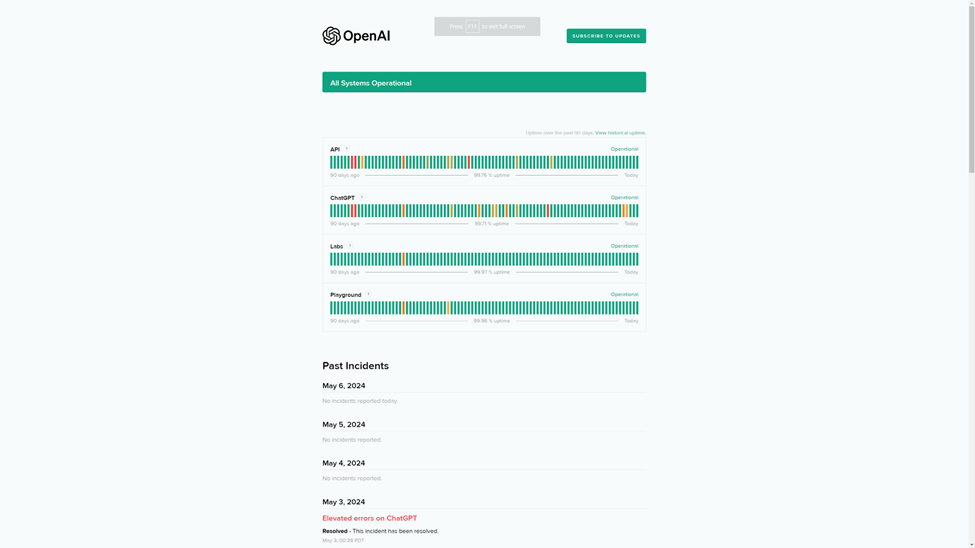
That means you need to prepare for 7+ hours of downtime every month. Addressing this requires a blend of good conversational UI and traditional software practices. Make sure you have sufficient retry logic built into your system. You will also want to clearly communicate back to your users when the system is incapable of responding.
Performance
LLMs can be slow, especially for long responses. Products like OpenAI offer streaming output, which can significantly reduce the perceived latency from the end user’s perspective. Latency can also be reduced by minimizing the number of output tokens as much as possible.
If you send data to other systems to do calculations or lookups performance can degrade even further. Users expect very low latency in conversational AI systems, so while this may seem obvious, it is critical that you optimize every component in your stack to be as fast as possible.
If latency is still an issue you will likely need to structure your UI to mitigate the impact on the end user. Consider immediately replying to a user letting them know you working on a task so you properly set expectations.
Cost
Finally, LLM pricing can be prohibitively expensive. Our LLM costs have become our largest expense beyond traditional cloud costs. The best way to manage costs is to use a federated approach.
Consider each challenge you’re addressing and question whether an LLM is truly the optimal solution. You might reap greater benefits from developing your own model for specific issues. This could be more cost-effective and potentially offer better performance. And remember, not every situation warrants the use of the most expensive LLM.
LLMs and Your Application
LLMs can significantly speed up your development. They can also enable you to tackle features that were previously beyond the capabilities of your team. However, LLMs are not a cure-all. If you want to build robust applications, you’ll need to invest a bit of extra effort. Happy building!