
I apologize! That title was actually generated by Microsoft’s speech recognition system incorrectly transcribing “Microsoft’s 5.1% Word Error Rate (WER) Announcement is Completely Misleading”. Okay, that was snarky, but I promise Microsoft compelled me to write that. You see in the course of editing my previous post Microsoft had to go and put out a press release announcing “Microsoft Researchers Achieve new Conversational Speech Recognition Milestone”. Their announcement flies in the face of my previous post and therefore I had no choice but to attempt an epic takedown.
Before I try to dismantle Microsoft’s irrational clam I would like to state that the the researchers at Microsoft (some of whom I have crossed paths with while working on the Xbox Kinect and HoloLens) have done some solid research with potential implications on how we build production speech recognition systems. I have no issues with the technical nature of the research paper underpinning the press release, but I do take issue with the marketing and PR spin applied on top of it. So without further ado “LET’S GET READY TO RUMBLE”.
There are two primary issues with the announcement made by Microsoft:
- Does Microsoft’s testing provide conclusive evidence that the 5.1% WER results will generalize
- Are the tactics used viable from a cost/compute/timeliness perspective in a production system
Let’s tackle each of these issues independently.
Will the Results Generalize
In my previous post I discussed why large data sets were critical for training truly accurate conversational speech recognition systems. While I do take issue with the data size used to train the Microsoft speech recognition system, the larger issue is with the test set used to validate the word error rate.
In Andrew Ng’s seminal talk on the “nuts and bolts of machine learning”, he goes into great detail on the different data sets required for training, testing and validating machine learning algorithms. I encourage anybody interested in the optimal process for training and testing machine learning / AI like algorithms to watch this seriously awesome video. In terms of Microsoft’s research I want to focus on the relatively small size of their test corpus, it’s overlap with the training data, and the fact that the chosen corpus appears cherry-picked.
Corpus Size
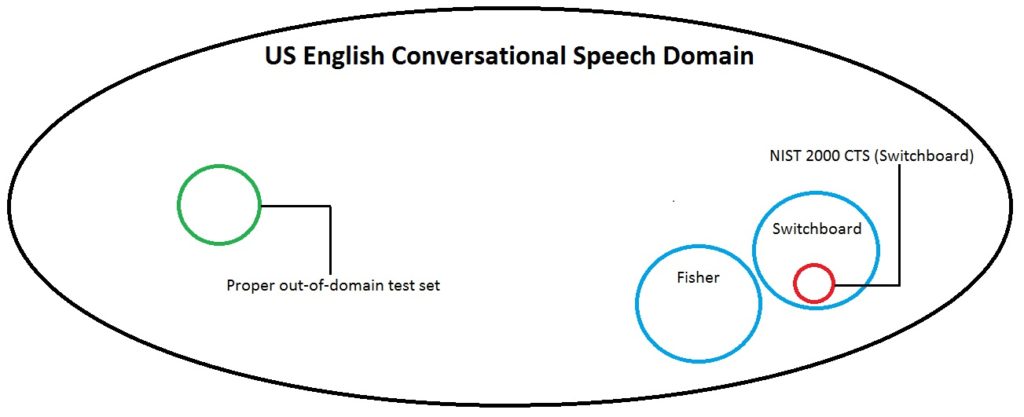
The test set Microsoft selected for calculating the reported 5.1% WER is the 2000 NIST CTS SWITCHBOARD corpus. While I was unable to find the specific number of hours of conversation in this test corpus I was able to confirm that the 1998 and 2001 NIST CTS data sets contained 3 and 5 hours of conversation respectively. We can therefore assume the number of hours of conversation in the 2000 set is similar in duration. When considering the overall size of the conversational speech domain explained in my previous post a test set of this size is hardly sufficient for making any broad claims about meeting or beating human transcription accuracy.
Training Data Overlap
As you dig into the details of the NIST corpus a dirty little secret is quickly revealed. Let me start by quoting directly from the source:
“Of the forty speakers in these conversations thirty-six appear in conversations of the published Switchboard Corpus.”
Let me translate that for you. Thirty-six of the speakers in the test corpus are the same speakers used in Microsoft’s training corpus. I’ll also remind you that the Switchboard corpus only has 543 speakers to begin with. This raises a foundational questions about whether the test data is really distinct relative to the training set. You see almost all modern speech recognition systems use something called i-vectors to help achieve speaker independence (sometimes called speaker adaptation). Since the same speakers, on the same devices, in the same environments exist in both the training and test corpus there will invariably be a correlation between the i-vectors generated by the two data sets.
Per the diagram below, a truly honest measure of WER would require the the test data be truly distinct from the training set . In other words it should pull from a data set that includes different speakers, different content, and different acoustic environments. What is clear from the Microsoft paper is that this didn’t happen which calls into question whether the published results will truly generalize. It also greatly diminishes the the validity of any claim about a new “milestone” being achieved in conversational speech recognition.
Cherry-picking
It’s worth noting that the full 2000 NIST CTS corpus actually contains a total of 40 conversations. Twenty of those conversations are from the Switchboard corpus and twenty are from a different corpus called “Call Home”. This begs the question of why Microsoft only validated against the Switchboard portion of the corpus. While I can’t say for sure what their intent was, my best guess is because if they had used the Call Home data the results would not have led to the desired goal of meeting or beating “human accuracy”.
Taken altogether, the small corpus, with overlapping data, and a cherry picked data set you can’t help but ask did Microsoft really achieve a “new conversational speech recognition milestone”?
Is it Production Ready
EBTKS. For those not familiar with texting slang, that stands for “Everything But the Kitchen Sink”, and it’s really the best description of the system Microsoft used for this research. This calls into question the production viability of their proposed solution.
Ensemble Models
At the acoustic model (AM) and language model (LM) layer Microsoft is using an ensemble model technique. This technique requires training multiple models and processing each utterance through every model. A separate algorithm is used to combine the outputs of the different models. In essence this equates to trying to run multiple recognizers at once for every audio utterance. It currently requires an enormous number of machines to transcribe phone calls in real-time at scale Microsoft appears to be running 4 distinct AMs and multiple LMs which will have serious performance impacts. This raises questions about the number of machines and associated costs required to run a system like the one used in Microsoft’s paper.
Language MODEL RESCORING
On top of the ensemble modeling Microsoft is also using language Model Rescoring. In order to rescore you usually have an initial language model produce an N-BEST lattice which is basically the top N paths predicted by the language model. This lattice needs to be stored or held in memory in order for the rescoring to take place. In Microsoft’s case they are generating a 500-best lattice. While not crazy holding a 500-best lattice in memory in a scaled production speech recognition system would not be ideal unless it provided significant accuracy gains. According to the paper the gains from rescoring were minimal at best.
In Conclusion
So where does that leave us? Microsoft has done some great research on advancing speech recognition algorithms. Research that I greatly appreciate and hope to review further. However for Microsoft to even imply that they achieved some epic milestone in matching human transcription accuracy is downright preposterous.
In the words of renowned Johns Hopkins speech recognition researcher Daniel Povey:
This was a good read. Thanks for the post.